恶意样本分析4-基础DLL分析
汇编及反汇编入门
基于基础动态分析有其局限,为了获取更深的洞察,需要代码分析(逆向分析) 例如,大多数样本使用c2服务加密通信。使用动态分析我们能够确定加密通信,但是无法获得其通信内容,因此我们需要了解如何进行代码分析。
动态和静态分析提供了了解恶意程序函数的好办法,单数不足以,提过所有关于恶意程序的信息。病毒坐着通常使用C或C++编写病毒程序,通过编译器编译。在你的调查过程中,你只有可执行的恶意程序,没有源代码。为了获得更深的关于恶意程序的内部工作和了解,代码分析是其至关重要的方面。
这一块最好提前拥有C语言的基础,及汇编基础。这一块的相关资源可在继续之前学习:
计算机基础、内存及CPU
数据转换,结构及位运算
分支和循环
功能和堆栈
数组,字符和结构
64x架构框架
本系列主要内容来自《K A, Monnappa. Learning Malware Analysis: Explore the concepts, tools, and techniques to analyze and investigate Windows malware. Packt Publishing. Kindle 版本. 》的记录
1. 计算机基础
计算机所有信息使用bits基本单位表示,1和0两种状态。bits的组合可以表示数字,字符以及任意信息。
数据种类基础 1 bytes=8 bits 0.5 bytes=1 nibble(bits) 1 word=2 bytes dword=4 bytes=32 bits quadword(qword)= 8 bytes=64 bits
数据解释 1 byte 或者 bytes 字节序列,能够被解释成不同的意思。 类似的2 bytes也可以被解释成不同的意思,汇编指令或者数字。 dword 也可以被解释成一串数或代表内存地址。如何被解释取决于如何使用它。
1.1 内存
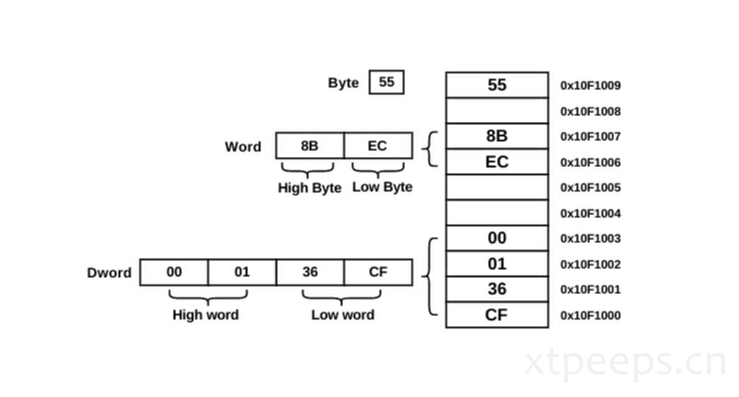
主内存(RAM)主要存储机器码以及计算机数据。RAM主要是一串字节(bytes)16进制字节序列,每个字节由地址标记。地址起始0终止于被使用量结尾。一个地址和值被16进制表示。
1.1.1 数据如何驻留内存
在内存中,数据存储被存储在低优先级的格式中;一个低位存储在低地址,字节序列被递归存储在内存高地址中。
1.2 CPU
CPU执行的指令通常称为机器指令,当需要取数据时从内存取数据。CPU包含一小块内存寄存器组。被用来存储在执行命令时从内存读取的数据。
1.2.1 机器语言
每个CPU有一套它能够执行的指令集。CPU执行的指令是由机器语言组成。机器指令被存储在内存作为字节序列被CPU获取,解释,执行。
编译器是一个用于将高级语言解释成机器语言的程序。
1.3 程序基础
1.3.1 程序编译
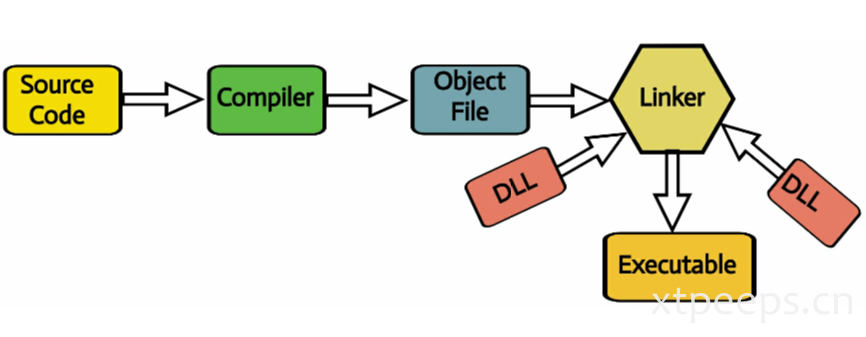
程序编译过程:
- C/C++编写代码
- 编译器编译成机器码或object文件
- 连接器linker将目标代码与DLL文件生成系统可执行的程序
1.3.2 运行在磁盘的程序
通过PE internals tools - PeInternals打开编译过的可执行程序,显示出通过编译器生成的五部分(.text,.rdata,.data,.rsrc,.reloc)。如静态分析里提到的内容相同。这里主要关注.text和.data两部分。
例如程序中存在一串字符。这些字符存储在.data部分在文件偏移0x1E00位置。这个字符不属于代码部分,但是属于程序需要的数据。相同的方式.rdata部分是只读数据和有时包含的(import/export)数据。.rsrc部分包含被执行程序使用的资源。
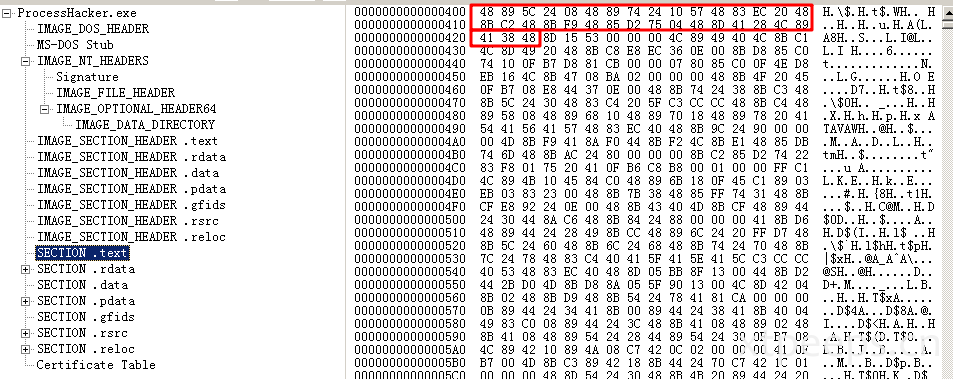 .text部分字节序列(具体来说是35字节)是从0x400开始的机器码。机器码中包含了CPU将要执行的指令。编译器编译之后会在存储时分为data和code两部分。
.text部分字节序列(具体来说是35字节)是从0x400开始的机器码。机器码中包含了CPU将要执行的指令。编译器编译之后会在存储时分为data和code两部分。
 为了简单起见在磁盘中的程序结构可以记为:可执行程序的组成部分就是code(.text)和data(data,.rdata等等)。
为了简单起见在磁盘中的程序结构可以记为:可执行程序的组成部分就是code(.text)和data(data,.rdata等等)。
1.3.3 在内存中的程序
当程序被加载到内存中时的情况。 过程: 双击应用程序之后,一个进程被操作系统分配到内存,并且可执行的被操作系统加载程序加载到分配的内存。下面的简化内存布局会帮助我们可视化概念;在磁盘中的结构和内存中的结构很相似。
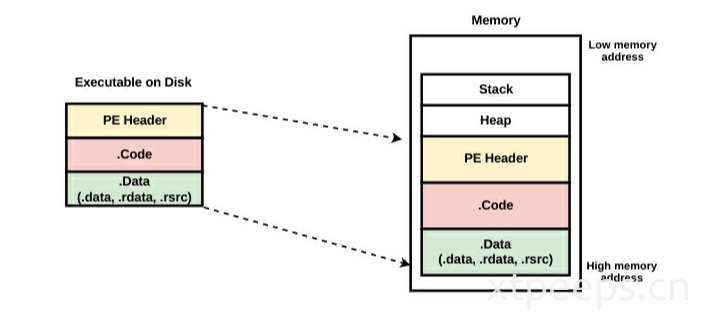
由图中可见,堆(heap)被用来在程序执行的时候动态分配内存,它的内容可以是变化的。堆被用来存储本地的变量,函数参数和返回的地址。内存还与链接库DLL有关。
使用x64dbg调试器https://x64dbg.com/#start 加载可执行程序到内存0x13FC71000,并且所有的可执行部分都加载到内存中。这个地址是虚拟地址。虚拟地址最终将会被翻译成物理地址。

检查.data部分开始记录的字符:一般会有"This is a simple program.",而我测试的这个hackprocess没有:


监测.text部分的内存地址,显示部分字节的机器码:

一旦可执行部分包含的code和data被加载到内存,cpu从内存中获取机器码,解释并执行它。当执行机器指令时会从内存获取数据data。
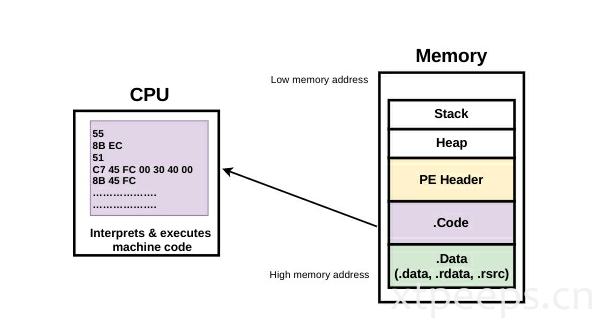 当执行指令时,程序可与输入输出设备交互。例如:在程序执行的时候,字符串被打印在电脑屏幕上。同样也可以接收字符。
当执行指令时,程序可与输入输出设备交互。例如:在程序执行的时候,字符串被打印在电脑屏幕上。同样也可以接收字符。
总结,当程序执行时经历了下面几步:
- 程序加载进内存
- CPU获取机器指令,解释并执行
- CPU从内存获取数据,数据可写入内存
- CPU可与输入输出设备交互
1.3.4 程序反汇编(从机器码到汇编指令)
由于机器码极不方便阅读,因此反汇编调试工具(IDA或者x64dbg)可以用来转换机器码到汇编指令,这样可以方便阅读及分析程序的工作。
2. CPU寄存器
CPU包含特殊的存储成为寄存器。 CPU访问寄存器里的数据比访问内存中的数据要快的多。因为内存中的数据要先拿到寄存器中再被CPU执行。
2.1 通用寄存器
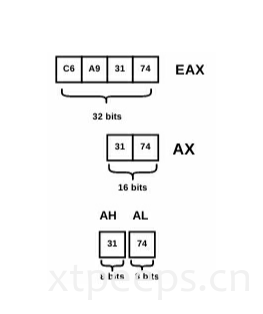
x86CPU有8个通用寄存器:eax,ebx,ecx,edx,esp,ebp,esi,edi。这些寄存器是32位(4字节)。程序可以获取寄存器32位,16位,8位值。每个寄存器的低16位(2字节)可以用ax,bx,cx,dx,sp,bp,si,di访问。eax.ebx,ecx,edx的低8位还可以通过al,bl,cl,dl引用。对应的高8位可以通过ah,bh,ch,dh访问。举例如下图所示:
2.2 指令指针(EIP)
CPU存在一个特殊的寄存器eip;它包含下一个要执行的的指令的地址。当指令被执行,eip将会指向内存中下一个将被执行的指令地址。
2.3 EFLAGS寄存器
eflags寄存器是32位寄存器,该寄存器的每一位都代表一个特殊含义的标记。eflags中的位使用来代表CPU运算中计算或控制的状态的。flag寄存器通常不直接引用,但是在执行计算或控制时,每一位会根据结果进行变化。
除此之外还有一些额外的寄存器被称为段寄存器:cs,ss,ds,es,fs,gs,被用来在内存中保持追踪的。
3. 数据转移指令MOV
通用的用法就是将src值移动到dst中:
mov dst,src3.1 移动常数到寄存器
移动常数或者立即数到寄存器 not part of the assembly instruction. This is just a brief description to help you understand this concept: mov eax,10 ; moves 10 into EAX register, same as eax=10 mov bx,7 ; moves 7 in bx register, same as bx=7 mov eax,64h ; moves hex value 0x64 (i.e 100) into EAX
3.2 移动值从一个寄存器到另一个
mov ebx,10 ; moves 10 into ebx, ebx = 10
mov eax,ebx ; moves value in ebx into eax, eax = ebx or eax = 103.3 移动值从内存到寄存器
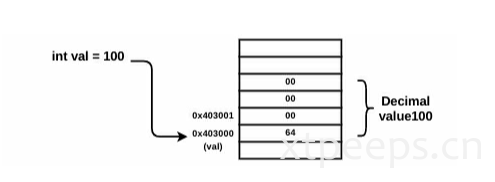
int val=100 在程序执行时发生的情况:
- 整数长度为4字节,因此整数100在内存中被存储为(00 00 00 64)
- 4字节序列被按照低位优先格式存放
- 整数100被存储在相同的内存地址下。
在汇编语言中,移动内存中的值到寄存器中,必须要使用值的地址。 方括号指定的时要保存的值在内存中的地址。
mov eax,[0x403000] ; eax will now contain 00 00 00 64 (i.e 100)这里无需指定4字节,基于目标寄存器的大小,CPU会自动确认需要移动多少字节。
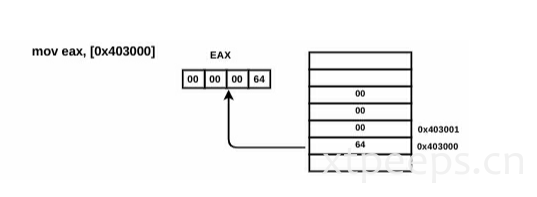
逆向过程中的其他类型还有如,方括号包含寄存器、常数+寄存器、寄存器+寄存器的形式。
mov eax,[ebx] ; moves value at address specifed by ebx register
mov eax,[ebx+ecx] ; moves value at address specified by ebx+ecx
mov ebx,[ebp-4] ; moves value at address specified by ebp-4- 另一个常见的指令lea指令 代表加载真实地址;这种指令会加载地址而不是值。将源地址传递给目的寄存器。
lea ebx,[0x403000] ; loads the address 0x403000 into ebx
lea eax, [ebx] ; if ebx = 0x403000, then eax will also contain 0x403000- 还可能会遇到 dword ptr 表明4字节(dword)值从ebp-4地址移动到eax:
mov eax,dword ptr [ebp-4] ; same as mov eax,[ebp-4]3.4 移动值从寄存器到内存
你通过移动操作数可以移动一个值从一个寄存器到内存,内存地址在目标位置在左边,寄存器在右边。
mov [0x403000],eax ; moves 4 byte value in eax to memory location starting at 0x403000
mov [ebx],eax ; moves 4 byte value in eax to the memory address specified by ebxdword ptr指定放入的格式4字节,word ptr指定2字节放入内存地址。
mov dword ptr [402000],13498h ; moves dword value 0x13496 into the address 0x402000
mov dword ptr [ebx],100 ; moves dword value 100 into the address specified by ebx,也就是00 00 00 64
mov word ptr [ebx], 100 ; moves a word 100 into the address specified by ebx,也就是00 64
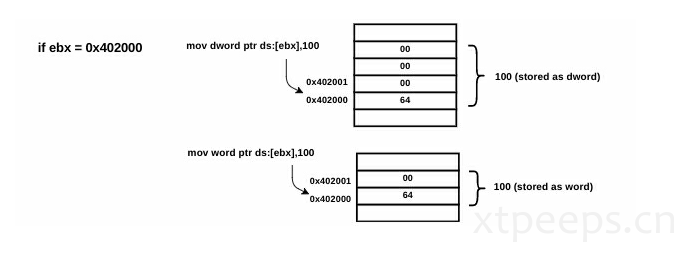
3.5 反汇编挑战
mov dword ptr [ebp-4],1 ➊;[ebp-4]=00 00 00 01
mov eax,dword ptr [ebp-4] ➋;eax=00 00 00 01
mov dword ptr [ebp-8],eax ;[ebp-8]=00 00 00 01,也就是把1给[ebp-8]3.6 反汇编解法
简单的方式理解反汇编代码,在对比c语言中,一个定义的变量实际上就是一个内存地址的象征名字。经过逻辑,然后可以定义内存地址给他们一个象征的名字。
内存地址,直接给一个标记名字,如[ebp-4]=a,[ebp-8]=b
say, ebp-4 = a and ebp-8 = b. Now, the program should look like the one shown here: mov dword ptr [a],1 ; treat it as mov [a],1
mov eax,dword ptr [a] ; treat it as mov eax,[a]
mov dword ptr [b],eax ; treat it as mov [b],eax在高级语言中你可以分配一个值给变量,val=1。在汇编中表示为mov [val],1
相同逻辑高级编程语言替换
a = 1
eax = a
b = eax ➍由于CPU使用寄存器暂存,因此还需要使用右边的标记值替换寄存器的名字,例如eax使用a替换
寄存器使用右边的复制标记值替换
a = 1
eax = a
b = a通过观察可以看到整个过程eax是作为暂时保存值使用的,因此,这里可以移除。
移除多余的语句
a=1
a=b在高级语言中,变量都有数据类别。尝试定义这些变量的数据类别。有时定义这些数据类别需要通过他们访问和使用的值来确定。从汇编语言中可以看到dword 4字节表示的1(也就是00 00 00 01)被移动到a变量中,之后又赋值给了b。因此知道a,b的类型是4字节dword,因此他们可能是int,fload或者pointer。
变量a,b不可能是fload,因为通过反汇编代码我们知道eax参与了数据操作的过程中。如果它是浮点值,那么标记寄存器一定会被使用,而不是使用通用寄存器eax。
而a,b不可能是pointer指针的原因是,他们赋值为1,一个常数,而不是一个地址,因此最终确定是整数类型。
确认变量的类型,结束
int a;
int b;
a=1;
b=a;对比原始c语言片段可以看到,并不是每次都可以反汇编出一模一样的代码,但是其语言的意思已经是无差别了。
int a=1;
int b;
b=a;如果反汇编一个大程序,标记所有的内存地址可能会很困难。尤其是使用反汇编或者调试器去崇明名内存地址然后执行代码分析。
当处理大程序的时候,好的做法是将程序拆分成程序块,然后分段反汇编,之后再用相同的方法去处理剩余的块。
4. 算数运算
加减乘除。
- 加减:add,sub。 这两个指令有两个操作数目的des和源src。都是用目的操作数加或者减源操作数,然后保存在目的操作数中,同时设置或者清除eflags寄存器的的标志位。 这些标记可以被用在条件语句。当sub执行之后等于0,zf标志位设置为0,并且如果目的操作数的值小于源操作数时,进位标志位cf,还应打标。
下面是几中命令变化:
add eax,42 ; same as eax = eax+42
add eax,ebx ; same as eax = eax+ebx
add [ebx],42 ; adds 42 to the value in address specified by ebx,ebx的地址加42
sub eax, 64h ; subtracts hex value 0x64 from eax, same as eax = eax-0x64特殊的加(inc)减(dec)命令,可被用于寄存器或者内存地址的加一或者减一操作。
inc eax ; same as eax = eax+1
dec ebx ; same as ebx = ebx-1- 乘法:mul mul只有一个操作数,使用al,ax或者eax寄存器乘以操作数,结果保存在ax或者dx+ax或者edx+eax寄存器中。 如果mul的操作数是8位二进制(1字节),则它使用8位al寄存器做乘法,然后结果存储在ax寄存器中。如果操作数使用的是16位二进制(2字节),则它使用16位ax寄存器做乘法,结果保存在dx和ax寄存器中。如果操作数是32位二进制(4字节),则它使用eax寄存器做乘法,结果保存在edx和eax寄存器中。结果保存在2倍大小的寄存器中是因为两个值相乘的结果将可能比输入大很多。
mul ebx ;ebx is multiplied with eax and result is stored in EDX and EAX
mul bx ;bx is multiplied with ax and the result is stored in DX and AX- 除法:div div也只有一个操作数,并且可以是寄存器也可以是内存引用。在执行除法过程中,需要把被除数放在edx和eax寄存器中,edx可以保存大部分重要的dword(32位4字节)。被除数放在eax中,除数放在ebx中对应位置,在div指令执行之后,商被保存在eax,余数保存在edx寄存器中。
div ebx ; divides the value in EDX:EAX by EBX。EAX/EBX=EDX(余数):EAX(商)4.1 反汇编挑战
mov dword ptr [ebp-4], 16h
mov dword ptr [ebp-8], 5
mov eax, [ebp-4]
add eax, [ebp-8]
mov [ebp-0Ch], eax
mov ecx, [ebp-4]
sub ecx, [ebp-8]
mov [ebp-10h], ecx练习: a=16h [ebp-8]=5 eax=16h eax=16h+5h=1Bh [ebp-0Ch]=1Bh ecx=16h ecx=16h-5h=11h [ebp-10h]=11h
int a=16h int b=5 int c,d c=a+b=1Bh d=a-b=11h
int a,b,c,d a=22; b=5; c=a+b=27; d=a-b=17;
答案原C语言代码:
int num1 = 22;
int num2 = 5;
int diff;
int sum;
sum = num1 + num2;
diff = num1 - num2;5. 按位操作
按位从最右侧开始编号,最右边(最低有效位)是0位的位置,从右向左按位提高。最左边位为最高有效位。如下所示:
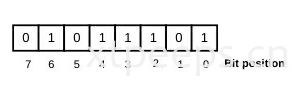 位操作不是指令;只有一个操作数(作为源和目的)和颠倒所有位。如果eax包含FF FF 00 00 (11111111 11111111 00000000 00000000),则下面的指令将会反转所以为。并存储在eax寄存器中。
位操作不是指令;只有一个操作数(作为源和目的)和颠倒所有位。如果eax包含FF FF 00 00 (11111111 11111111 00000000 00000000),则下面的指令将会反转所以为。并存储在eax寄存器中。
not eax- and,or,xor指令执行对应位操作并且保存在目的地址中。 cl和bl进行and操作执行,将会按位相与,得出结果保存在bl中。
and bl,cl; bl=bl&cl
or eax,ebx ; same as eax = eax | ebx
xor eax,eax ; same eax = eax^eax, this operation clears the eax register- 逻辑shr(右移) 和shl(左移) 指令 有两个操作数(目的和记数)。目的操作数可以是寄存器也可以是内存关联地址。这些指令与c或者python中的shift left («)或者shift right(»)很像。
shl dst,count逻辑位移指令,顺序左移或者右移,最高位移到cf中,最低位0补充。
- 特殊的:xor eax,eax 常用于清除eax的值
关于位操作的引申阅读: https://en.wikipedia.org/wiki/Bitwise_operations_in_C https://www.programiz.com/c-programming/bitwise-operators.
- rol(循环左移) 和ror(循环右移) 与shift执行相似,只是移出的位添加到另一边。例如左边移出的位添加到右边。
6. 分支和条件
if/else和 jump jump有两种:有条件和无条件
6.1 无条件跳转
无条件跳转常用到jump。机器码jmp。这与C中的goto类似。下面的质量将控制跳转到jump address(跳转地址)并从此处开始执行:
jmp <jump address>6.2 有条件跳转
在控制跳转时,控制转入一个内存地址需要基于一些条件。你需要执行变更标志(重置或则清除)。这些指令可以执行算数运算或者位运算。在x86指令提供cmp指令,从第一个操作数(目的操作数)减第二个操作数(源操作数)将结果保存在目的操作数中,同时修改标志位。在接下来的指令中,如果eax为5,cmp eax,5 则eax-5=0 将会设置flag(zf位为1):
cmp eax,5 ;# eax-5设置flags但是结果不保存另一个指令改变标志位flags但是不保存结果:test指令。test指令执行1比特操作and同时改变标志位并不存储结果。
test eax,eax;cmp,test指令都带有jump指令判定,可以跳转。 几种jump指令变种:
jcc <address> ;cc为条件格式,条件基于在eflags寄存器中比特位。下面是不同类型跳转条件及别名以及标志位使用表:
| 指令 | 描述 | 别名 | 标志位使用 |
|---|---|---|---|
| jz | jump if zero | je | zf=1 |
| jnz | jump if not zero | jne | zf=0 |
| jl | jump if less | jnge | sf=1 |
| jle | jump if less of equal | jnle | zf=1 or sf=1 |
| jg | jump if greater | jnle | zf=0 and sf=0 |
| jge | jump if greater or equal | jnl | sf=0 |
| jc | jump if carry (如果有进位) | jb,jnae | cf=1 |
| jnc | jump if not carry(如果不进位) | jnb,jae |
6.3 if语句
从逆向的角度,识别分支和条件声明是很重要的。为了做到识别有必要了解清楚再汇编语句中如何实现分支和条件声明(如if,if-else,if-else if-else)的汇编语言。
if (x==0){
x=5;
}
x=2;==对应not equal to (jne)
cmp dword ptr[x],0
jne end_if
mov dword ptr[x],5
end_if:
mov doword ptr[x],2
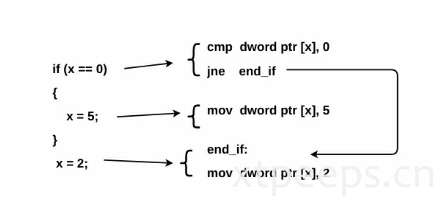
6.4 if-else语句
if(x==0){
x=5;
}
else{
x=1;
}cmp dword ptr[x],0
jne else
mov dword ptr[x],5
jmp end
else:
mov dowrd ptr[x],1
end:6.5 ifleseif-else 语句
if(x==0){
x=5;
}
else if(x==1){
x=6;
}
else{
x=7;
}cmp dword ptr[ebp-4],0
jnz else_if
mov dword ptr[ebp-4],5
jmp short end # 段内短转移,修改范围:-128~127,"short"说明进行短转移。
else_if:
cmp dword ptr[ebp-4],1
jnz else
mov dword ptr[ebp-4],6
jmp short end
else:
mov dword ptr[ebp-4],7
end:6.6 反汇编练习
mov dword ptr [ebp-4], 1
cmp dword ptr [ebp-4], 0
jnz loc_40101C
mov eax, [ebp-4]
xor eax, 2
mov [ebp-4], eax
jmp loc_401025
loc_40101C:
mov ecx, [ebp-4]
xor ecx, 3
mov [ebp-4], ecx
loc_401025:x=1
if (x==0)
{
x=x^2;
}
else{
x=x^3;
}7. 循环
最常见的两个循环for和while。
/*for 循环*/
for(初始值;条件;更新语句){
代码块
}
/*while 循环*/
初始化
while(条件){
代码块
}示例:
int i=0
while(i<5){
i++;
}mov [i],0
while_start:
cmp [i], 5
jge end
mov eax, [i]
add eax, 1
mov [i], eax
jmp while_start
end:7.1 反汇编挑战
mov dword ptr [ebp-8], 1
mov dword ptr [ebp-4], 0
loc_401014:
cmp dword ptr [ebp-4], 4
jge short loc_40102E
mov eax, [ebp-8]
add eax, [ebp-4]
mov [ebp-8], eax
mov ecx, [ebp-4]
add ecx, 1
mov [ebp-4], ecx
jmp short loc_401014
loc_40102E:int x=1;
int y=0;
while(y<4){
x=x+y;
y++;
}8. 函数
参数,局部变量和函数控制流都保存在内存的栈中。
8.1 栈
栈是当操作系统线程创建的时候由操作系统制定分配的内存中的一块区域。栈后进先出(LIFO,Last-In-First-Out)。通过push,pop,来对栈进行压栈和弹栈操作,分别对应压入4byte和从栈顶弹4byte值操作。
push source; 将源(source)压入栈顶
pop destination; 将栈顶值弹出到目的地址(destination)栈从从高地址向低地址增长。当一个栈被创建,esp寄存器(也被称为栈指针)指向栈顶(逻辑上的高位,但从地址来看是指向栈里值中最低地址那位),当执行push操作将数据压入栈中,esp寄存器则指向比压入数据更低位的(esp-4)地址。当执行pop后,esp则加4(esp+4)。
举例:
/*假设esp 初始指向0xff8c*/
push 3 //esp-4
push 4 //esp-8
pop ebx //esp-> esp-4
pop edxebx=4 ,edx=3, esp最后指向初始位置
8.2 调用函数
call 函数名汇编在调用函数之前将下一需要执行指令地址保存在栈中。并在函数调用结束之后从栈中弹出地址继续执行。
8.3 函数返回
汇编中函数返回使用ret命令,该命令执行pops将弹出栈顶的地址,取出的值放在eip寄存器。
ret8.4 函数参数和返回值
在x86架构中函数的参数被压在栈中,返回值在eax寄存器中被替代。
int test(int a, int b)
{
int x, y;
x = a;
y = b;
return 0;
}
int main()
{
test(2, 3);
return 0;
}main:
push 3
push 2
call test
add esp, 8 ; after test is exectued, the control is returned here
xor eax, eax
test:
push ebp //栈顶指针,指向本函数在栈的栈顶,用于函数执行完返回函数入口地址继续执行,执行之后esp会自动减4,压栈使用
mov ebp,esp //ebp/esp同时指向栈顶,ebp用作固定位置,应用使用ebp关联函数参数和局部变量
sub esp,8 //为x,y分配空间
//---实际上函数代码----
mov eax,[ebp+8]
mov [ebp-4],eax
mov ecx,[ebp+0Ch]
mov [ebp-8],ecx
//-------
xor eax,eax //eax清0,return 0,返回值通常保存在eax
//---还原函数环境---
mov esp,ebp
pop ebp
//-------
retpush ebp和mov ebp,esp经常出现在函数的开始,可以被称作函数的序或者函数的开始。是函数用来初始化函数使用的。
mov esp,ebp和pop ebp执行函数的序逆向操作。成为函数尾声,在函数执行之后恢复环境。
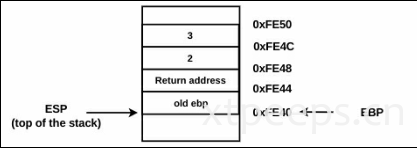
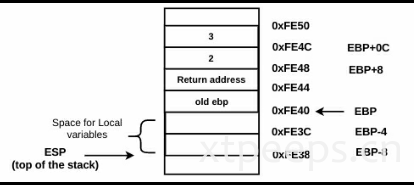
ebp在这里被设置为固定位置,函数的参数可以通过ebp+正向偏移量进行标定。局部变量可以通过ebp-偏移量进行标定。举例上面test(2,3),函数参数2,被存储在ebp+8(a)位置,第二个参数被存储在ebp+0xc(b),局部变量分别放在ebp-4(x),ebp-8(y)。
大部分编译器(如Microsoft Visual C/C+ 编译器)使用固定ebp堆栈结构去关联函数参数和局部变量。GNU编译器(如gcc)默认不用ebp堆栈结构,而是使用ESP(栈指针)集群器做呗关联函数参数和局部变量。
pop ebp之后将恢复ebp保存在栈中的值,这个操作之后,esp将会+4。再执行了还原函数环境操作之后:
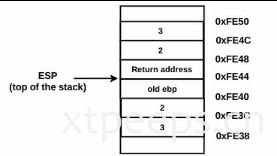
当ret执行之后,返回地址在栈顶,被弹栈到eip寄存器中。控制器返回到主函数执行地址中(在主函数中add esp,8)。在弹栈到返回地址中之后,esp+4。在这点,控制器被控制返回主函数执行。主函数main中的add esp,8用于清理栈,esp返回到最开始的位置(0xFE50)。add esp,8这样的函数称为cdecl传统调用。
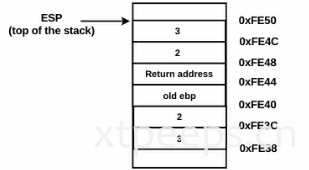
大部分C语言编译器都遵循cdecl调用惯例。在cdecl惯例中,调用者将变量以从右到左的规则压栈到栈中,调用者caller自身在调用函数之后清除自身。也有其他调用规则,例如stdcall和fastcall。在stdcall规则中,变量通过caller调用者和callee被调用者从右到左的规则压入栈,调用函数callee负责清理栈。Microsoft windows使用stdcall规则处理被dll文件输出的API函数。在fastcall调用规则中,开始一些参数通过直接存放在寄存器被传递给函数,剩下的所有参数通过以从右到左的方式压入栈中,并且与stdcall类似被调用者callee负责清理栈。(后面会特别的看到64位程序使用fastcall调用规则)
9 数组和字符串
数组是由相同类型数据组成的一个列表。数组元素在内存中连续存储,便于访问数组中的元素。下面的定义一个含有3个元素的整数型数组,每个元素在内存中占用4字节(因为一个常数是4字节长度):
int nums[3]={1,3,4}数组的名是一个指向数组第一个元素的指针常量(数组名指向数组的基址base address)。访问数组需配置相对基址相对地址(原文叫:index)类似nums[1]:

在汇编中,数组中的任何一个元素的地址计算需要三个东西:
- 数组的基址
- 元素的相对地址
- 数组中每个元素的大小
高级语言中nums[0]对应转化为汇编的[nums+0*<每个元素的大小字节>],前面的例子对应的各元素的汇编则为:
nums[0]=[nums+0*4]=[0x4000+0*4]=[0x4000]=1
nums[1]=[nums+1*4]=[0x4000+1*4]=[0x4004]=3
nums[2]=[nums+2*4]=[0x4000+2*4]=[0x4008]=4一般访问数组元素的形式或公式为:
[base_address+index*size of element]
9.1 数据反汇编挑战
push ebp
mov ebp, esp
sub esp, 14h
mov dword ptr [ebp-14h], 1
mov dword ptr [ebp-10h], 2
mov dword ptr [ebp-0Ch], 3
mov dword ptr [ebp-4], 0
loc_401022:
cmp dword ptr [ebp-4], 3
jge loc_40103D
mov eax, [ebp-4]
mov ecx, [ebp+eax*4-14h]
mov [ebp-8], ecx
mov edx, [ebp-4]
add edx, 1
mov [ebp-4], edx
jmp loc_401022
loc_40103D:
xor eax, eax
mov esp, ebp
pop ebp9.2 反汇编解决方法
反汇编:
int main(){
int num[2]={3,2,1}
int b,i
for(i=0;i<3;i+1){
b=num[3-i];
}
return 0;
}这里汇编for和while语句无区别,可参考在两个c语言for和while循环生成汇编代码之后的区别看出https://my.oschina.net/firebroo/blog/406286 因此反汇编也无区别
书里是使用的while语句循环做的反汇编:
int main()
{
int a[3] = { 1, 2, 3 };
int b, i;
i = 0;
while (i < 3)
{
b = a[i];
i++;
}
return 0;
} 反汇编分析:
//---函数开场(非代码)---
push ebp
mov ebp, esp
//---函数开场结束---
sub esp, 14h //分配局部变量(非代码)
//---代码段---
mov dword ptr [ebp-14h], 1
mov dword ptr [ebp-10h], 2
mov dword ptr [ebp-0Ch], 3
mov dword ptr [ebp-4], 0
loc_401022:
cmp dword ptr [ebp-4], //循环对比条件
jge loc_40103D //循环结束跳转条件,人工判断loc_40103D为结束循环
mov eax, [ebp-4] //[ebp-4]被初始化为0
mov ecx, [ebp+eax*4-14h] //代表数组内容访问,根据标准格式调整应该为[ebp-14h+eax*4],ebp-14h为数组的基址,数组元素大小为4比特。
mov [ebp-8], ecx
mov edx, [ebp-4]
//循环变量增加
add edx, 1
mov [ebp-4], edx
//循环变量增加结束
jmp loc_401022 //循环语句
loc_40103D:
xor eax, eax
//---代码段结束---
//---函数结尾清理---
mov esp, ebp
pop ebp
//---函数结尾清理结束---9.3 字符串
字符是字符数组,当定义一个字符串的时候,一个空终止符(字符串终止符)被加在每个字符串的结尾。每个元素占用内存一个字节(换句话说,每个ASCII码1字节长)。
char *str="aaaaaaaaaaaaaaaaaa"字符串名字str是一个纸箱字符串第一个元素的指针(指向字符阵列基址指针)。下图为字符串在内存中的图表:
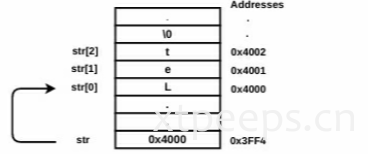
str[0]=[str+0]=[0x4000+0]=[0x4000]=L
str[1]=[str+1]=[0x4000+1]=[0x4001]=e
str[2]=[str+2]=[0x4000+2]=[0x4002]=t字符串一般表达式:
str[i]=[str+i]9.3.1 字符串指令
x86框架的操作系统提供字符操作用于字符串处理。这些命令的步骤通过字符串(字符数组)和加后缀b、w、d等,表示操作的数据的大小(1,2或4字节)。字符串命令使用eax,esi和edi寄存器。eax或者其子寄存器ax,al用于存放数值。寄存器esi作为源地址寄存器(保存源字符串的地址),edi作为目的地址寄存器(用于保存目的字符串地址)。
执行字符串操作之后,esi和edi急促那期都自动增加或者减少。方向标志位(DF——direction flag)在eflags寄存器决定了esi和edi是否需要增加或减小。cld指令清除方向标志位标志(df=0);if df=0,则索引寄存器(esi和edi)增加。std指令设置方向标志位标志(df=1);在这里esi和edi减小。
9.3.2 移动内存到内存(movsx)
movsx指令用于移动一段内存序列从内存一处到另一处。 movsb指令被用于移动1字节数据通过esi寄存器地址移动到指定的edi寄存器地址。 movsw,movsd指令移动2,4字节数据通过esi寄存器地址移动到指定edi寄存器地址。 当数据值被移动,esi和edi寄存器增加或减小基于数据大小的1,2,或4字节。下面是一个例子:
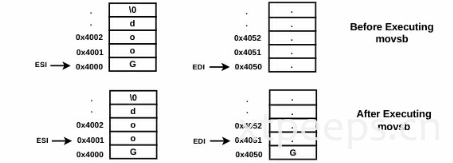
lea esi,[src] ; "Good",0x0
lea edi,[dst]
movsbmov —-为数据传送指来令,可以在寄存器(立即数)、内存之间双向传递数据。 lea —-取内存单元自的有效地址指令,只用于传送地址。
假设地址标签src内容为"good",以空字符(0x0)结尾。在执行第一个命令后,esi将会包含"good"的第一个字符的地址(esi指向"g“所在的地址),第二个指令执行之后,将会设置EDI的内容为dst。第三个语句执行将会复制1字节从esi指向的地址数据到edi指向的地址数据。执行借宿esi和edi都将加1。
9.3.3 重复指令(rep)
movsx指令只能复制1,2,或4字节数据。复制更多字节内容则使用rep指令。rep指令使用ecx寄存器,并且重复执行ecx指定次数的字符串操作指令。下面的汇编代码是复制"good"从src到dst:
lea esi,[src] ; "Good",0x0
lea edi,[dst]
mov ecx,5
rep movsbrep指令,当使用movsx指令,等效C语言中的memcpy()函数。rep指令有多种形式,并且在执行循环中基于条件允许提前终止。下面的表格内容为不同形式的rep指令和他们含义:
| instruction | condition |
|---|---|
| rep | 重复指令直到ecx=0 |
| repe,repz | 重复直到ecx=0或者zf=0 |
| repne,repnz | 重复直到ecx=0或zf=1 |
9.3.4. 将寄存器中值存到内存中(stosx)
stosb指令用于从CPU的al寄存器中移动1字节的数据到edi指定的内存地址中(目的索引寄存器)。stosw和stosd指令分别用于移动2字节和4字节地址到edi指定的内存地址中。通常stosb指令与rep指令被用于初始化所有缓冲区字节为相同的某值。下面的汇编代码使用5个双字节填充目的缓冲区,值都为0(换句话说初始化了5*4=20字节的内存空间为0)
mov eax,0
lea edi,[dest]
mov ecx,5
rep stosd9.3.5 从内存中加载数据到寄存器中(lodsx)
lodsb指令从esi指定的内存地址(源索引寄存器)中加载到al寄存器总。lodsw和lodsd指令是移动2字节和4字节数据从esi指定的内存地址中到ax和eax寄存器中。
9.3.6 扫描内存(scasx)
scasb指令用来搜索或扫描1字节的值在字节序列中存在或者不存在。要搜索的字节存放在al寄存器中,缓存内存地址存放在edi寄存器中。scasb指令常与repne指令(repne scasb)连用,ecx设置缓存长度;重复直到每个字节在al寄存器中找到或直到ecx变为0。
9.3.7 对比内存中的值(cmpsx)
cmpsb指令被用于对比esi指向的内存地址中的1字节值和edi中的值对比,以判断是否是相同的值。cmpsb通常和repe一起用(repe cmpsb)对两个内存缓存;在这种情况下,ecx为缓存的长度,对比将会一直持续到ecx=0或者缓存不相等。
10 结构
一个结构组是不同种类的数据放在一起;每个结构中的元素成为一个成员。结构体成员通过常量偏移访问。举个便于理解的C语言例子,静态结(simple struct)定义包含三个成员不同数据种类的变量(a,b和c)。主函数main定义结构变量(test_stru),结构体的变量地址(&test_stru)作为第一个参数传递给update函数。在update函数中,成员的值被更新为被指定变量值:
struct simpleStruct
{
int a;
short int b;
char c;
};
void update(struct simpleStruct *test_stru_ptr) {
test_stru_ptr->a = 6;
test_stru_ptr->b = 7;
test_stru_ptr->c = 'A';
}
int main()
{
struct simpleStruct test_stru; ➊
update(&test_stru); ➋
return为了了解结构体成员如何存储,我们考虑update函数的反汇编情况。
push ebp
mov ebp, esp
mov eax, [ebp+8] ➌
mov dword ptr [eax], 6 ➍
mov ecx, 7
mov [eax+4], cx ➎
mov byte ptr [eax+6], 41h ➏
mov esp,ebp
pop ebp
retmov eax,[ebp+8]结构体的基址传递到eax寄存器(注意:ebp+8代表第一个参数;第一个参数代表结构体的基址)。mov dword ptr [eax], 6通过基址加偏移量0指定为第一个成员赋值整数值6([eax+0]与[eax]相同)。由于整数占用4字节,第二个成员为short in值为7(存储在cx)通过基址+4被指向第二个成员。第三个成员为基址+6传递值为41h(A)。
通用的结构体成员的地址表达式可以总结为:
[base_address+constant_offset]
结构体与数组在内存中看起来类似,但是需要记住他们指针的区别:
- 数组元素的数据都是相同类型的,结构体的成员并不一定都是相同的类型
- 数组的元素大部分通过基址和变量访问(如[eax+ebx]或[eax+ebx*4]),答案是结构体大部分通过基址及偏移量访问(如[eax+4])
11. x64架构
x64架构是x86架构的一个扩展和延伸。并且与x86指令设置类似,但是从代码分析的角度有一些不同。这一部分包括x64架构的一些不同点:
- 32位(4字节)通用寄存器eax,ebx,ecx,edx,esi,edi,ebp和esp被扩展到64位(8字节);这些寄存器名字变为rax,rbx,rcx,rdx,rsi,rdi,rbp和rsp。8个新寄存器的名字为r8,r9,r10,r11,r12,r13,r14和r15。一个程序可以以64位(RAX,RBX等),32位(eax,ebx等),16位(ax,bx等)或者8位(al,bl等)访问寄存器。例如,你可以访问RAX寄存器的下半部分作为EAX,RAX的四分之一或更低位作为AX寄存器使用。可以通过在寄存器名字后附加b,w,d或q以字节,字,双字或4字节访问r8-r15。
- x64框架可以处理64位(8字节)数据,所有地址和指针都是64位(8字节)大小。
- x64位CPU有64位指令指针(rip)包含下一个要执行的指令地址,并且还有64位的标志寄存器(rflags),但是通常只有32位被使用(eflags)。
- x64架构支持rip-relative地址。rip寄存器现在可以被用来关联内存位置;你可以在当前指令指针加偏移访问数据。
- 其他主要的不同是在x86架构中,函数参数被压栈到栈中,因此在x64架构中,前4个函数参数被存放在rcx,rdx,r8,r9寄存器中,如果函数需要额外的寄存器,则他们被存放在栈中。下面是个C的例子:
printf("%d %d %d %d %d",1,2,3,4,5)
32位(x86)中编译,所有的参数都被压倒栈中,在调用pringf之后, add esp,18h清除栈。
push 5
push 4
push 3
push 2
push 1
push offset Format ; "%d %d %d %d %d"
call ds:printf
add esp, 18h在64位(x64)处理器中编译,在寄存器中分配0x38(56字节)栈空间。前4个变量被存放在rcx,rdx,r8和r9寄存器中。第五和第六个参数被存放在栈中,使用mov dword ptr [rsp+28h], 5; mov dword ptr [rsp+20h], 4。push指令并不会出现在此例子中,这会使判断地址是否是局部变量还是函数参数更困难一些。在这个例子中,字符格式帮助确定printf函数的参数的数量,单数其他情况中中不太容易判断:
sub rsp, 38h ➊
mov dword ptr [rsp+28h], 5 ➐
mov dword ptr [rsp+20h], 4 ➏
mov r9d, 3 ➎
mov r8d, 2 ➍
mov edx, 1 ➌
lea rcx, Format ; "%d %d %d %d %d" ➋
call cs:printf如果遇到未提及的相关指令则可以参考最新intel 架构手册 https://software.intel.com/en-us/articles/intel-sdm, 指令设置相关 (volumes 2A, 2B, 2C, and 2D) 可以在下面下载https://software.intel.com/sites/default/files/managed/a4/60/325383-sdm-vol-2abcd.pdf.
11.1 32位可执行程序在64位windows上分析
64操作系统可运行32位可执行程序;实现其功能是通过开发了一个被叫做wow64子系统(windows32位子系统在windows64位操作系统中)。wow64子系统允许32位二进制在64位操作系统中运行。当执行程序是,如果需要加载DLL调用API函数与系统交互。32位执行程序并不会加载64位的DLLs(64位程序也不会调用32位DLLs),因此微软将DLL分成32位和64位两部分。64位二进制被存储在\windows\system32目录下,32位二进制被存放在\windows\syswow64目录下。
在进行了对比之后发现,32位程序在64位windows中运行的行为可能会与原生32位执行的不同。当分析32位恶意样本在64位操作系统中时,可能会发现样本实际上访问的是 system32目录,而不是syswow64目录(操作系统自动重定向syswow64目录)。如果一个32位恶意程序(在64位windows环境下)向\windows\system32目录中写入文件,那么需要检查在\windows\syswow64目录。因为访问%windir%\regedit.exe会重定向到%windir%\SysWOW64\regedit.exe中。因此会有可能造成分析过程中理解困难,为了避免类似情况最好还是在32位运行32位二进制,64位在64位运行。
wowo64子系统如何影响你的分析的一文中可以看到更详细的分析http://www.cert.at/static/downloads/papers/cert.at-the_wow_effect.pdf
12. 其他资源
Learn C: https://www.programiz.com/c-programming C Programming Absolute Beginner’s Guide by Greg Perry and Dean Miller x86 Assembly Programming Tutorial: https://www.tutorialspoint.com/assembly_programming/ Dr. Paul Carter’s PC Assembly Language: http://pacman128.github.io/pcasm/ Introductory Intel x86 - Architecture, Assembly, Applications, and Alliteration: http://opensecuritytraining.info/IntroX86.html Assembly language Step by Step by Jeff Duntemann Introduction to 64-bit Windows Assembly Programming by Ray Seyfarth x86 Disassembly: https://en.wikibooks.org/wiki/X86_Disassembly
总结
在本章我们了解了汇编语言执行的代码以及必要的技术。并对比了x86和x64的框架区别。反汇编和反编译技巧将会有助于后续的理解样本分析工作。